The previous article discussed the cost of owning a mess, why good code is important, and how we can improve and prepare the codebase to require less effort in future changes thanks to refactoring.
We still have things to grasp. One of them was motivated after listening to a chapter about refactoring on the SyntaxFM podcast, Highly recommended podcast, at some point Scott said something that confuses me for a moment.
"...another benefit you could gain from refactoring here is performance enhancement..."
I get what Scott is saying but performance is more related to optimization and that's why we'll discuss in this article what are the differences and similarities between optimization and refactoring and why often when we refer to "optimizing code" we are actually talking about refactoring.
What confuses people: Both alter code
Refactoring
Refactoring is the discipline used to alter the code without changing the observable behavior. The goal is to refine the code having as criterion simplicity, readability, and maintainability.
👨💻 Impact on users
After refactoring, the software keeps working as usual, and the changes remain unnoticeable to the users.
Since the changes happen at a structural level (code), only the team involved is aware of the changes.
👩🏫 Example
Before
if (orientation === ORIENTATION.PORTRAIT ||
orientation === ORIENTATION.PORTRAIT_UP ||
orientation === ORIENTATION.PORTRAIT_DOWN) {
// Put your logic here
}
The above example may not seem challenging to read, but imagine having that piece of code spread all over your code. Whenever you see an if that starts with the same comparison, you'll lose time verifying it's the same if statement; otherwise, how to be sure it is doing the same?
To avoid that mental overhead and take advantage of reusability, we can put that comparison inside a function and use its name to reveal the intention.
function isPortrait(orientation) {
return (
orientation === ORIENTATION.PORTRAIT ||
orientation === ORIENTATION.PORTRAIT_UP ||
orientation === ORIENTATION.PORTRAIT_DOWN
);
}
Now instead of having the same if statement repeatedly. We'll replace it with a call to the new function. Since the function is self-explanatory, it's easy to get what it does.
After
if (isPortrait(orientation)) {
// Put your logic here
}
Unfortunately, not all refactors are as easy to do; many involve breaking dependencies, writing or rewriting classes, protecting our code from third-party libraries, implementing abstractions, and even deleting unnecessary code.
Optimization
Optimization has a different purpose. Its goal is to improve software's performance. Generally involves satisfying a specific metric to accomplish a nonfunctional requirement . The metric could be to reduce memory, CPU usage, or response time; it depends on the problem you're trying to solve.
👨💻 Impact on users
Same as with refactoring: Change the code, not what it does
Users may detect something has changed even when the functionalities remain the same. This effect happens when the difference after the optimization compared with before is too evident.
The most noticeable changes are when the application responds faster, can handle more concurrent operations or doesn't hang when a heavy file is loaded.
👩🏫 Example
In JavaScript when people want to reverse a string usually we write a function like the following:
// Reverse string using built-in array's function
function reverseString(str) {
return str.split('').reverse().join('');
}
Since in JS strings don't have a reverse method but arrays do, we rely on the built-in functions split and join to convert the string into an array and use its reverse method to finally join the reversed array into a string again.
The above code solves the problem but there are more performant solutions like converting the string into an array and swapping the elements at both sides:
// Reverse string via swapping elements in-place
function reverseString(str) {
const chars = str.split('');
const length = chars.length;
let temp;
for(let i=0; i <= Math.floor(length/2); i++) {
temp = chars[length - i - 1];
chars[length -i - 1] = chars[i];
chars[i] = temp;
}
return chars.join('');
}
If we were offering this functionality as a parsing utility, users wouldn't notice any change in the results unless they work with huge strings. In that case, they would witness the app takes less time to finish or not hang anymore when working with larger strings.
Why it's important to know the differences?
 (source: Working Effectively with legacy code, page 7)
(source: Working Effectively with legacy code, page 7)
During our careers, we'll spend the majority of time working to preserve behavior, either by refactoring or optimizing code.
Therefore, it's important to understand their differences and tradeoffs to make better decisions.
In the reverseString example, the most used solution was the first, even when the second performed better. Why is that?
💡 Hint : What do you think we invest more time as devs? Reading code or writing code?
We spend more time reading!. Therefore, unless optimizing resources becomes a crucial task to the project, we'll always prefer an unoptimized and straightforward solution instead.
Take the increasing use of map, filter, and reduce array methods in JavaScript as reference. Apparently, for loops are no longer accepted even when demonstrated to be more efficient; that's because these array methods are much simple to understand compared with an imperative solution.
const prospects = devs
.filter(dev=> /python/gi.test(dev.experience))
.map(dev => ({
phone: dev.phone,
firstName: dev.firstName,
lastName: dev.lastName,
email: dev.email,
socialMedia: dev.socialMedia
}));
OR
const prospects = [];
for (int i = 0; i < devs.length; i++ ) {
if(/python/gi.test(devs[i].experience)) {
prospects.push({
phone: devs[i].phone,
firstName: devs[i].firstName,
lastName: devs[i].lastName,
email: devs[i].email,
socialMedia: devs[i].socialMedia
}
}
Although both pieces of code do the same. There is a natural inclination to the first example. Maybe it's due to the explicit actions filter and map, which lower the bar to understand what the code does.
Using filter and map creates new arrays on memory by default, making it an inefficient solution when working with massive collections compared with the implementation that uses a for loop.
The above examples reveal a certainty regarding optimization:
There are always tradeoffs between readability, simplicity, and the optimal use of resources
The above statement explains wh refactoring and optimization compete to generate the best outcome.
It's up to you to decide based on the system, users, and developer's needs what aspect deserves more attention at a given time.
Free to decide or forced to comply?
A difference between these two concepts is when to pursue them.
Both disciplines are designed to solve someone's pain:
🔧 Refactoring solves the developer's pain of dealing with and working on complex code. In the long run, it prevents inheriting those problems to customers by making the system unreliable and unstable due to the difficulty of maintaining existing functionalities while adding new ones.
🚀 Optimization solves a user's or customer's pain. Another reason is to comply with an agreement between who provides the software and who's paying for it.
Refactoring problems are often more visible than optimization problems due to being interacting every day with the code. Still, since the latter affects people who are paying for the software, it has a higher priority in the majority of cases.
Affecting customers' work or not fulfilling contract clauses gives code optimization a whole different level of urgency.
Optimization is always made when required, not before, and involves a clear objective.
On the contrary, since refactorization is developers' problem (until is not), and their needs have a lower priority than business people, customers, and users, it's up to the team to explain the effort invested and decide when to do it.
Since time is money, and to avoid " convincing" non-developers that the teams need time to conduct refactors. A good option is to do these changes on every user story when they still involve a small effort and low risk.
It is like having a mindset of cleaning as you go.
Refactoring should be done frequently on every task, a little every time. That way, we ensure the refactor risk, cost, and effort remains low
Limited or continuous?
When optimizing code, we are clear on one thing: The desired metric's value.
Knowing the magic number doesn't tell you anything about achieving it. The team needs to brainstorm what to do, choose an idea and get hands-on to see if it works. If not, the process is repeated.
As you can see, achieving an optimization goal can consume a lot of time. One strategy is to limit the time spent on every idea to get a fast outcome. The team decides whether to invest a few hours or days per idea until the goal is eventually met.
Due to the complexity that represents reaching the magic number, never try to go beyond that, or you could find yourself in an impossible crusade.
Now, what about refactoring? I'll explain it through a hypothetical case:
Imagine that your code is a house, and every time you see something bad or that could be better, you represent it with a defect in the house. It might be a broken window, paint damage, a missing door...
 (Source: Tim Arterbury, on Unsplash @tim_arterbury )
(Source: Tim Arterbury, on Unsplash @tim_arterbury )
If you do nothing, your house will lose all of its value at some point.
But, if only you could repair immediately any damage by replacing the broken window, repainting the house, and installing a new door where it was missing. You'd be spending less money and effort to maintain the high value of your house.
The same analogy works with gardening. You must remove the weeds, move the earth, and water the plants, all of this regularly, otherwise, your garden will lose all its beauty, and in extreme cases, it can die.
Refactoring should be done regularly, like gardening. But keep in mind that plants are going to die either way if you're watering them once a month.
Refactimization or Optifactoring?
We know now that these disciplines are designed to address different purposes, and each one affects the counterpart.
Although you can benefit both by targeting the golden mean.
You can do some refactorizations without impacting the performance, like the one we saw at the beginning of this blog post. We can rename variables, extract methods, modularize the code, or remove duplicated code.
👩🏫 Example
2-dimensional arrays are a widely used data structure, also known as Matrix.
Images are often represented using 2-dimensional arrays.
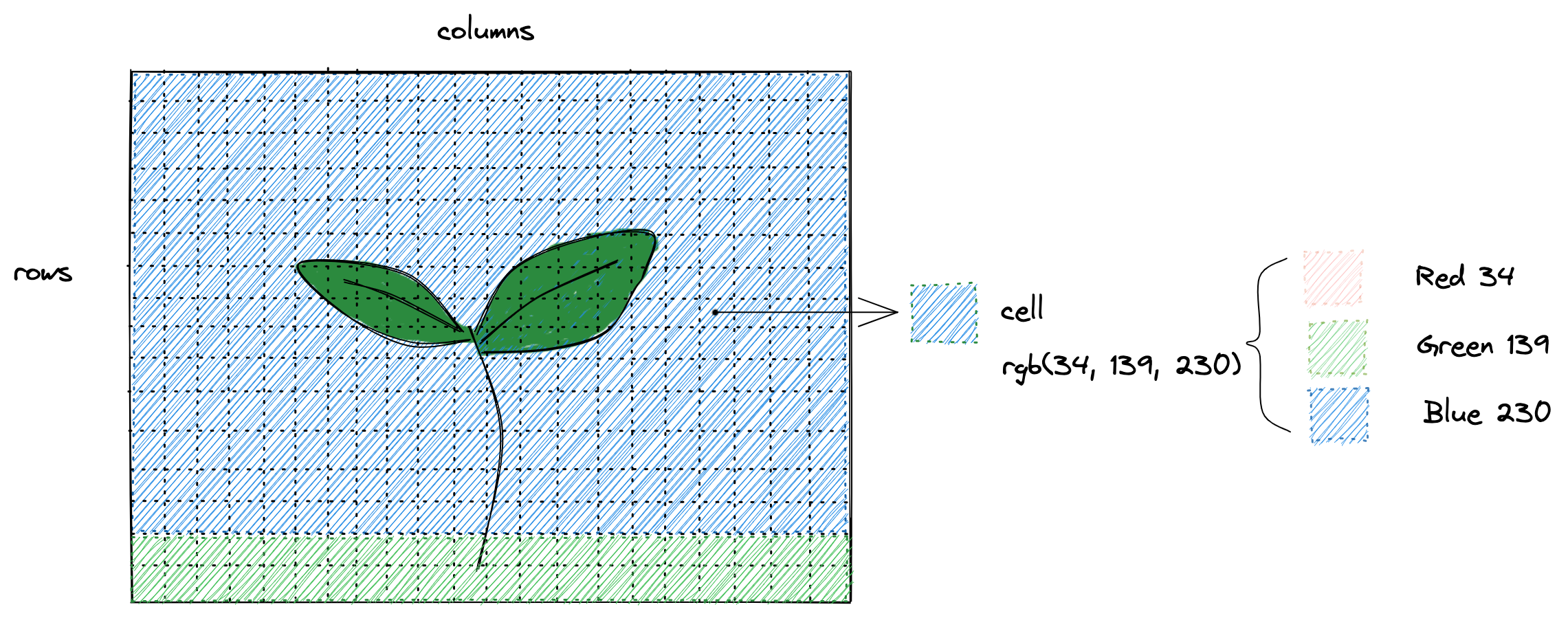
For example, a picture of 1920x1080 has 1920 rows and 1080 columns.
1920x1080 = 2073600 cells!
Each cell contains a color represented in RGB (Red, Green, Blue) with a 3-tuple, the first value for the red channel, the second as the green, and the last as the blue. Each value could be between 0 and 255.
2-dimensional arrays are easy to understand by humans, but operations over these arrays tend to have an O(n^2) complexity. A linear approach O(n) would be better to reduce the processing time on large images.
A simple optimization is to encode the 2-dimensional array into a 1-dimensional by remembering the splits to identify cells as part of different rows within a single array.
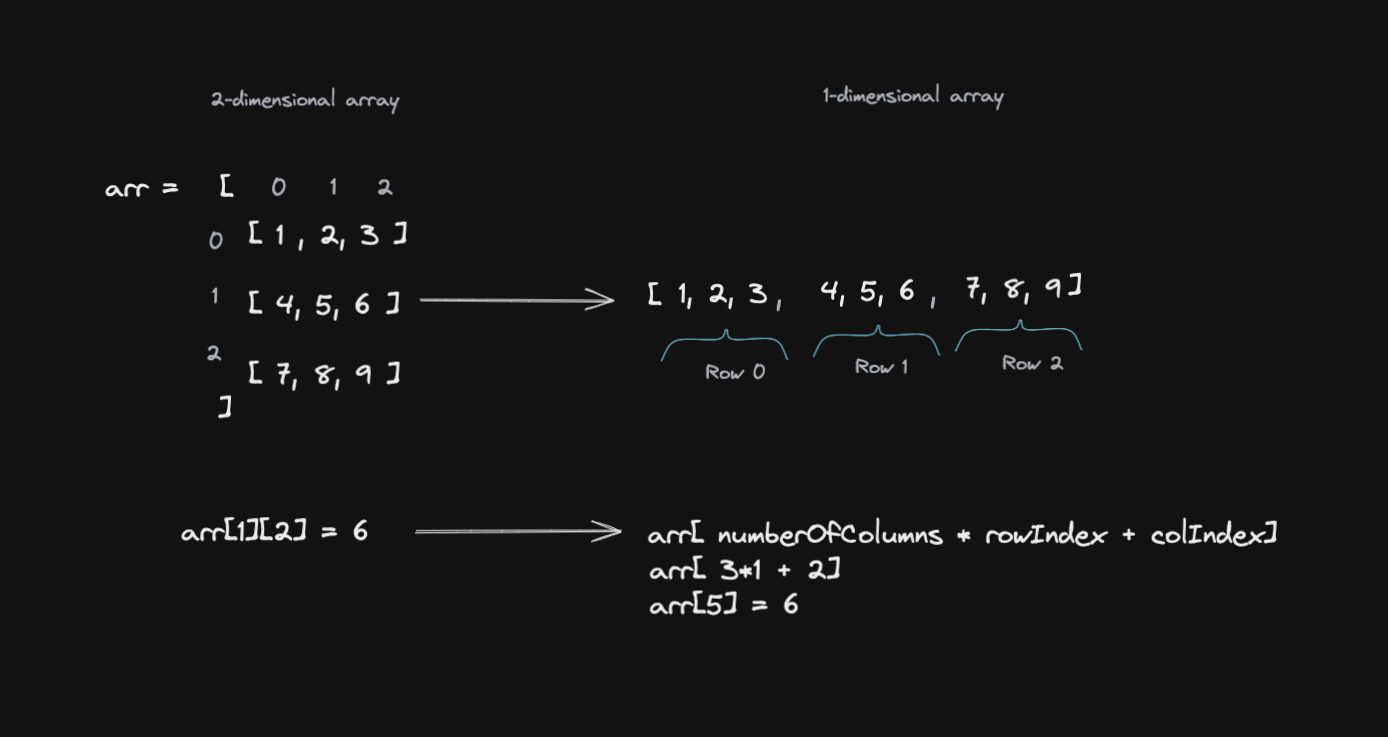
Doing the above process every time we need to deal with images is challenging. In order to make the developer's life easier, we can refactor that code to hide the encoding process behind a class. That way, anyone using that class will think it is dealing with 2-dimensional arrays, but they won't know the story is different internally.
We offer specialized methods to retrieve each cell and perform common matrix operations in the class.
class SquareMatrix {
private cells: number[] = [];
private mColumns: number;
// Encode Bidimensional array into a one-dimensional array
SquareMatrix(arr: number[]) {
let i = 0;
let j = 0;
while(i < arr.length**2) {
if(j === arr.length) {
j = 0;
i++;
}
this.cells.push(arr[i][j]);
j++;
}
// Since it's a square matrix the number of columns is the
// same as the number of rows
this.mColumns = arr.length;
}
public cell(rowIndex: number, colIndex: number): number {
return this.cells[this.mColumns*rowIndex + colIndex];
}
/*
.
.
.
*/
}
The end result is an optimized code that's readable and hide complexity through a public API (The class's public methods).
const matrixA = new SquareMatrix([
[1,2,3],
[4,5,6],
[7,8,9]
]);
matrixA.cell(0,0) // 1
matrixA.cell(1,2) // 6
matrixA.cell(2,2) // 9
const matrixB = new SquareMatrix([
[1,2,1],
[0,1,1],
[3,2,0]
]);
const matrixC = matrixA.add(matrixB);
To simplify the example above, we assume that the encoding would suffice, but in a real scenario, we need to test the change and if it works, only then refactor. We can use the optimization metric to control the refactoring by knowing if we are getting worse than what we achieved with the optimization.
The other way around is more difficult because optimizing the software can diminish the refactoring benefits done, and we don't have any metric to know when that happens.
Conclusions
- Refactoring and optimization are not the same
- Both have different purposes, although they both change the code without changing the observed behavior
- In the case of optimization, users may detect something has changed because the application got faster or can handle more operations
- Optimization always has a deadline, and it's scoped while refactoring is up to the devs to decide when they should do it, although the best approach is to incorporate this discipline daily
- Both disciplines can be combined, considering that focusing on one will affect the other. It's a matter of finding the golden mean.
- A suggestion is to always apply refactoring at last. Because there are always changes to do that won't affect the optimization accomplished.